|
Until version 0.1.2, kHTTPd had an Apache-like architecture: A number of threads was handling one request each. This model is simple to program, but it had severe disadvantages when a lot of requests were being handled: The system spent a considerable time in the scheduler. 15000 reschedules per second was no exception. In the 2.2.x days, this was expensive. In the 2.3.x kernel, considerable work is done to reduce the schedule-overhead, so it might just be that this architecture will perform again in the near future. The current (version 0.1.3 and above) architecture resembles the architecture of Zeus and tHTTPd. There is one single thread (per CPU) that handles all requests.
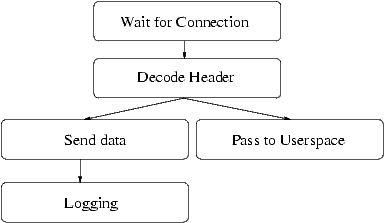
Every request in the request-queue has a state associated with it.
The lifecycle of a request, in terms of state-transitions, is shown in the
graphic below. This has the advantage of modular design; each of the states has its own C file, has one interface to the main-file and can be replaced without affecting the other states. CaveatsThis design has some caveats that must be dealt with:
High-load behaviorUnlike the old architecture, this architecture schedules less with increasing load. Under extreme load (over 2000 requests per second), the daemon schedules hardly at all. Effectively, under low load, the daemon operates in an interrupt-driven way, while under high load, it operates in a polling way. |